Using agents effectively for product work
How I use agents to inspect product truth from inside a codebase, then connect analytics, support, releases, attribution, model evaluation, and growth work without handing over product judgment.
A metric looks wrong. A release feels risky. Paid traffic is moving while revenue stalls. A support thread sounds like a bug and may just be one user's setup. A model looks cheaper; the real question is whether it makes the product worse.
I use agents most in that gap: as a way to inspect the product from inside the codebase while keeping product judgment with me.
The useful shift came from making the codebase a better place for the agent to find product truth.
I ask things like:
- Why did purchase intent drop yesterday?
- Are users reaching their first real transcription?
- Is the latest release healthy?
- Which settings do people actually choose?
- Did the landing-page experiment move download intent?
- Which support threads are really product feedback?
- Can a local model replace this cloud model without making the product worse?
Those questions sometimes end in code changes. They start as product questions.
The Unit Of Work Is A Product Question
Most coding-agent workflows start with an implementation request:
Add this button.
Fix this bug.
Refactor this file.
That workflow is useful. The more interesting work starts one layer above it:
I do not trust this metric. Figure out why.
This release feels risky. Check the actual health path.
We got a support complaint. Is it a one-off or a product issue?
Paid traffic is up. Is revenue following, or are we just buying noise?
This model looks cheaper. Does it actually make the product worse?
These questions cut across code, analytics, revenue, support, release infrastructure, local logs, and whatever messy state exists on the machine that day.
Agents can help here only if the product is legible to them.
An instruction like "check the dashboard" breaks down when the dashboard is stale, two metrics measure different populations, the event name is ambiguous, revenue lives somewhere else, or a support thread has the real answer.
So much of the work has been making those boundaries explicit.
The Codebase Is Not Just Source Code Anymore
My codebase has slowly become an operator manual for the product.
It tells the agent:
- which worktree to use
- which branch is for app work
- which docs define the current event taxonomy
- which analytics source is trustworthy for which question
- which metrics must not be mixed
- where revenue lives
- where support truth lives
- how to validate a release
- where local app logs are written
- which old systems are archival and should not be used for routine reporting
Mundane, but load-bearing.
Most product analysis dies in mundane places.
It dies because someone mixes two populations and calls it a funnel. It dies because a download click gets treated as revenue intent. It dies because a stale export is easier to query than the current source of truth. It dies because one broad event gets interpreted as one specific product moment. It dies because "support says this is broken" actually means one screenshot in one thread that nobody expanded fully.
I encode those boundaries.
For example, product questions in my repo have a routing map. Product usage goes to the product analytics source. Event joins and attribution go to the warehouse. Revenue goes to the billing system. Support starts from the full customer thread. Paid spend comes from the ad platform. Download starts come from first-party download logs.
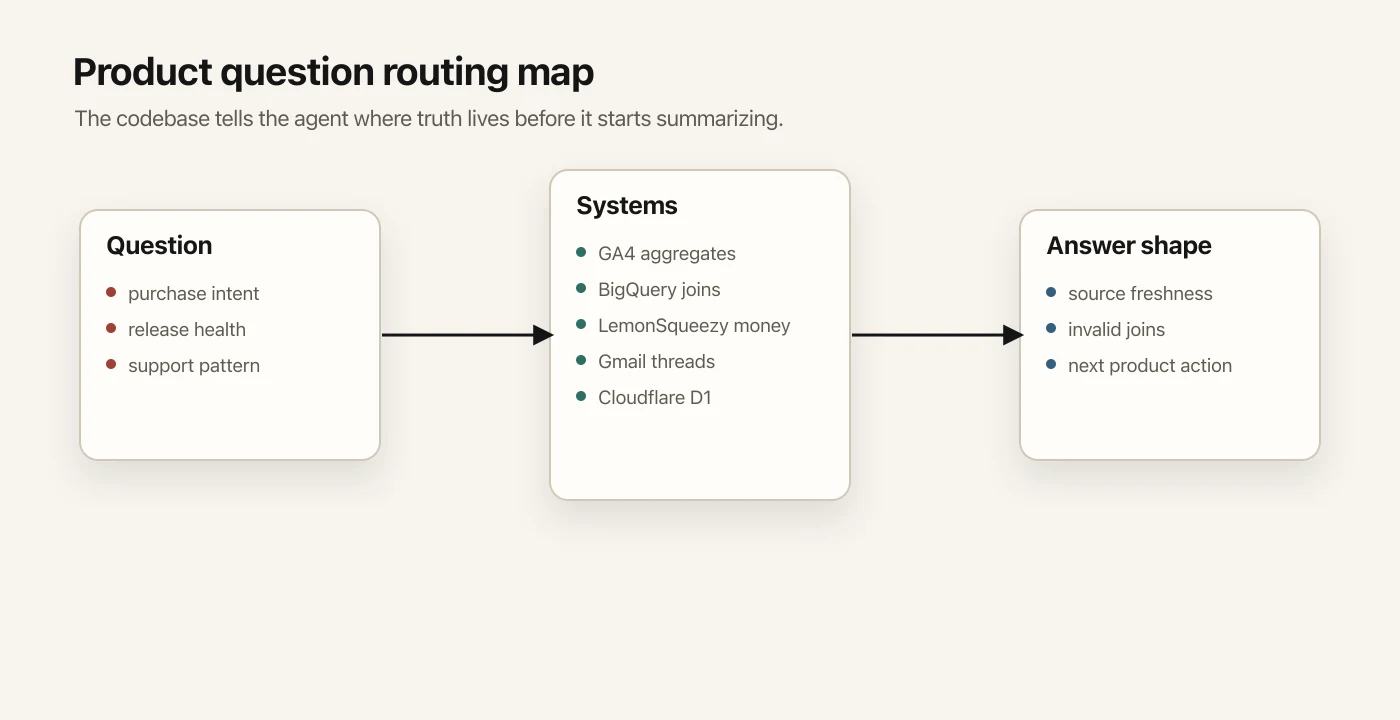
There are also rules:
- Do not calculate conversion rates across different telemetry populations.
- Do not treat website traffic as app-version adoption.
- Do not use revenue proxies when live revenue is available.
- Do not trust old attribution paths for routine reporting.
- When two systems disagree, name the system of record and say what is stale.
This is the unglamorous part that makes the agent usable.
The agent became better at product work when the product became easier to inspect.
When The Agent Cannot Answer, The Product Is Under-Instrumented
One of the most useful moments is when the agent hits a product instrumentation gap.
I once asked which setting users actually chose after opening a configuration screen. The agent could find that people touched the setting. The event did not carry the final choice.
So the task changed.
It was no longer "analyze hotkey behavior." It was "make hotkey behavior observable."
We added the missing choice detail to the existing event.
Small change technically. Full pattern operationally:
Ask a product question. Hit a visibility gap. Patch the product so the question can be answered next time.
The same thing happened with the paywall.
At one point, a paywall event was too broad. It mixed several surfaces. A paywall shown inside settings and a paywall shown during an active workflow are different product moments. Treating them as one event made the analysis look cleaner than it really was.
The fix was better product language in the telemetry: separate events for separate surfaces.
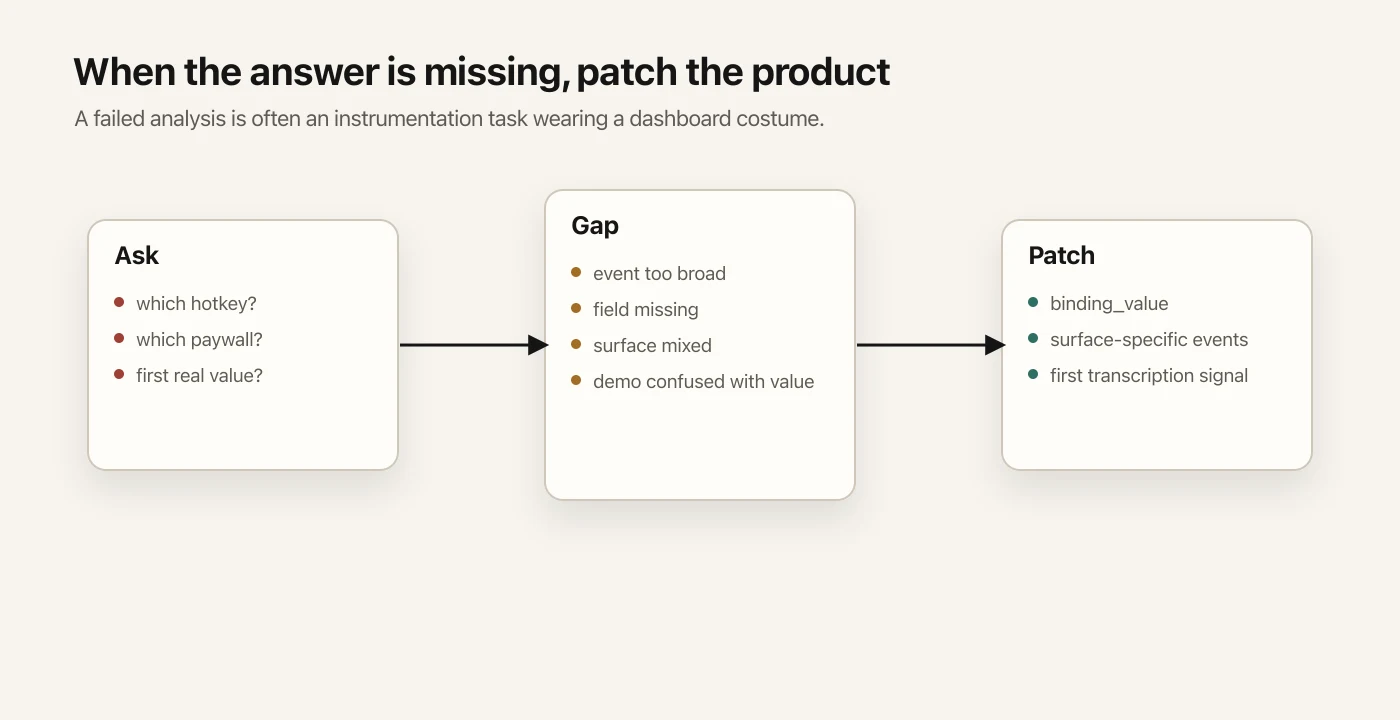
Now the agent can answer a better question:
Is this specific paywall surface working?
instead of pretending the umbrella event means what I want it to mean.
Onboarding had a similar issue. A demo transcription during onboarding can succeed while the user still never reaches real value in their actual workflow.
So the product needed a first-real-transcription signal.
If the agent cannot answer a product question, the product may need a better signal.
Product Health Is A Standing Question
Some questions should not wait for me to remember to ask them.
"Is the product working end to end?" is one of them.
I have a product-health loop that checks the product across the actual user journey:
- Can people reach the website?
- Are they showing intent?
- Can they download the app?
- Can they reach checkout?
- Are purchases coming through?
- Can new users install and complete onboarding?
- Are they reaching first real transcription?
- Is everyday dictation working?
- Are the AI-assisted features healthy?
- Are model downloads failing?
- Are updates being checked and downloaded?
- Is the current release crashing?
The product-health loop is flow-first.
The question is not "how many events fired?" The question is "which product promise might be broken?"
The report changes shape around the product promise.
Website reach, download, checkout, onboarding, first value, and everyday usage are P0 flows. If one breaks, the product or business is materially impaired. AI features, model delivery, update delivery, license health, and crash health are P1 flows. They matter for trust, retention, and release quality even when they are not first-session blockers.

The monitor is also strict about sources. It can use product analytics, warehouse queries, download telemetry, install/update telemetry, revenue records, crash data, health endpoints, and local repo scripts. It is told not to scan archival exports unless there is an incident.
It is a lot of plumbing.
Without that plumbing, an agent will do what agents often do: produce a confident summary from whatever source was easiest to reach.
The report I want says:
This is green.
This is watch.
This is broken.
This source is stale.
This metric is opt-in only.
This cannot be joined safely.
I would rather have that than a polished dashboard screenshot.
Paid Acquisition Is Not A Dashboard Screenshot
Ads are another place where the agent is useful only when it understands the product path.
The question I care about is not:
How much did ads spend?
The question is:
Did paid traffic produce buying intent and revenue?
That requires separating layers:
- spend
- clicks
- website quality
- download starts
- installs
- checkout intent
- purchase success
- paid orders
- revenue
- attribution lag
These live across multiple systems.
The ad platform has spend. Product analytics has traffic and product events. Download logs have first-party download starts. The billing system has money. The warehouse is where joins can happen. Each source has caveats.
Agents are good at this kind of tedious reconciliation when the rules are explicit.
For example, a download attempt is only an early signal. A checkout click is still pre-revenue. An ad-platform conversion can be directionally useful while the billing system remains the system of record for money.
This pushed me away from an earlier attribution model.
The previous approach tried to stitch everything: ad click, website session, DMG download, installed app, later checkout session. It was attractive because it promised precision.
In practice, it leaked.
Trackers get blocked. Download tracking is incomplete. macOS metadata recovery is incomplete. Users purchase later from a different browser session. The system was trying to preserve a level of exactness the product path did not reliably support.
The replacement is less exciting and more useful:
- attribute installs to campaign cohorts
- persist the cohort in the app
- carry it into checkout
- report revenue by cohort
It gives up false precision and gives the agent something durable to reason from.
This is an important lesson for agentic product work:
Coarser truth beats precise fiction.
Support Is Product Data
Support is where this stops being an analytics story.
The customer thread is the truth for support. It is a poor operating surface for an agent.
A thread can be missed. A message-level search can hide the latest reply. Support replies can come from multiple identities. A manually maintained support ledger can drift. Two inbox searches can produce two different versions of product state.
So the support workflow changed.
Instead of making the agent rediscover support state every time, code does the deterministic part:
- search candidate support threads
- fetch full customer threads
- normalize messages
- classify latest customer/support state
- merge curated notes
- generate support snapshots
- cache thread reads
The agent should not be the reconciliation engine.
The agent should start from reconciled state.
Then it can do the higher-level work:
- summarize what needs response
- draft replies
- connect support patterns to product issues
- identify feature-request candidates
- preserve operator judgment in curated notes
Support work has real consequences, so this split matters.
In one refund case, the important work was not writing code. The agent had to identify the exact customer, verify the order, make sure the refund actually happened, and prepare the customer reply.
That is product work.
It touches customer trust, billing, operational tools, and the product's support memory.
No part of that is glamorous. All of it matters.
A Release Is Not Done When The Patch Lands
One language-related release is a good example of why I think of this as product work, not coding work.
The issue was simple: transcription should respect the selected language. The support signal said the product was behaving as if the wrong language had been selected.
The agent traced the runtime paths:
- selected language
- app settings
- runtime configuration
- settings UI
- language-change analytics
- tests around supported languages
Then came validation: checking the supported language set, running a multilingual smoke test, and running focused settings tests.

The work continued past the patch.
The release still had to move through versioning, release notes, release config, build, signing, packaging, update delivery, download links, and email-preview boundaries.
Then launch follow-through had to connect back to measurement.
A directory listing or launch post also has a measurement job. A plain URL gives weak attribution. A tagged URL makes the launch measurable through download, install, checkout, and revenue.
The valuable part is that the agent can carry a customer issue across diagnosis, code, validation, release, distribution, and measurement without dropping as much context between steps.
Experiments Should Stay Cheap Until They Deserve More
A landing-page experiment was deliberately small.
The question was narrow:
Should one audience see a different landing hero?
The answer was not to replace the global homepage.
The practical version was:
- keep the global homepage unchanged
- serve a hidden variant for the test audience
- route internally based on the experiment rule
- preserve hydration with a variant cookie
- compare against baseline rates
- avoid deciding from a tiny sample unless checking for obvious breakage
An agent helps here because the work crosses product judgment and implementation details: the product idea, the routing layer, the analytics events, the sample size, and the rollback condition.
The experiment then got folded into the product-health loop, so it could be checked alongside the rest of the product.
A one-off experiment becomes part of the operating system if it matters.
Model Evaluation Should Use Product Data
Agents are useful around model work when they avoid benchmark theater.
For one AI-assisted feature, I asked for the exact prompt and output contract. The useful answer had to find the literal source, active version, default model, and expected output shape.
That matters because model behavior is product behavior. If the prompt changes, the product changes.
Then came the more interesting question:
Can a local model replace or compete with the cloud model?
The lazy version of that task would be a few synthetic prompts.
The useful version used real Speakmac transcripts.
The agent compared a local model against the current baseline, then generated a review page with raw input, output, diffs, and failure notes. That made the evaluation inspectable. I could see what changed and whether the tradeoff was acceptable.
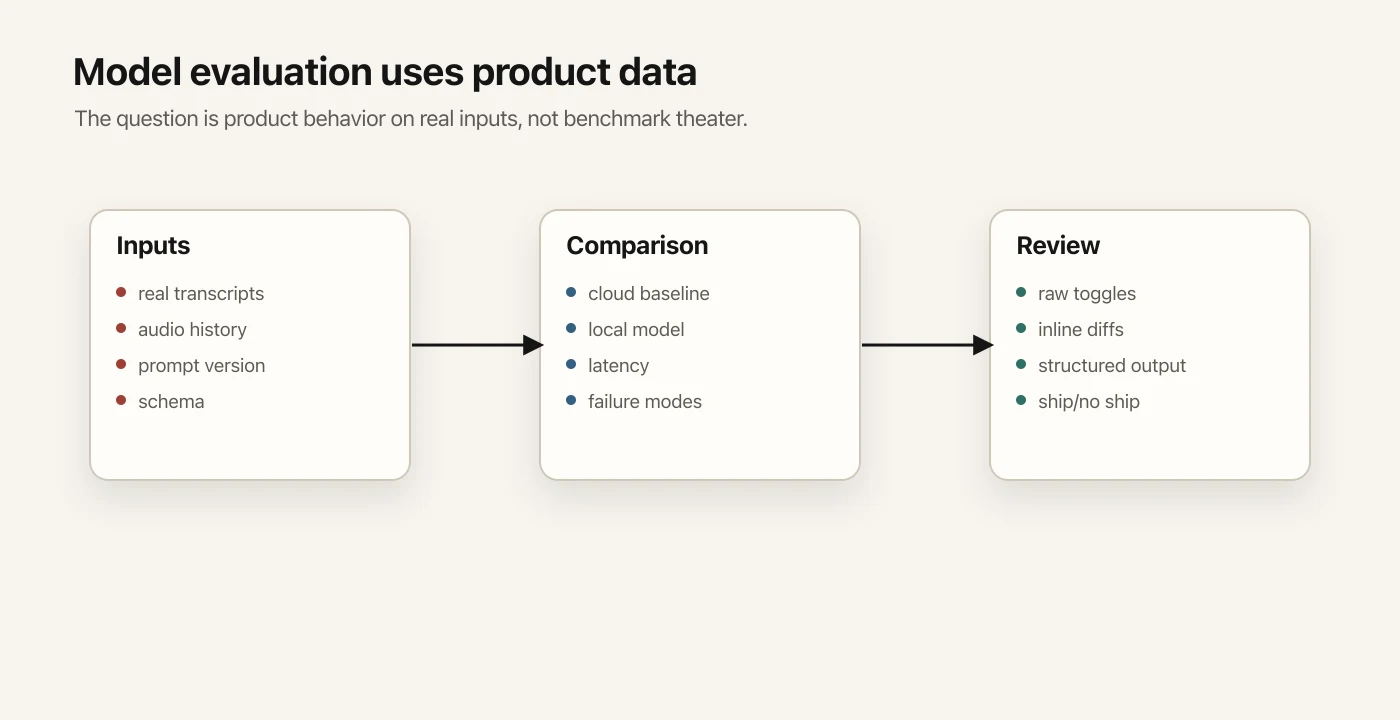
The same principle applied to ASR evaluation.
Instead of relying on leaderboard numbers, the agent used actual product inputs. It compared models on preserved examples, measured latency, tracked where the examples came from, and produced review pages.
The difference between model benchmarking and product evaluation is the source of truth.
The product cares about performance on its real inputs, latency constraints, failure modes, and user expectations.
Content And Growth Are Product Surfaces Too
This also applies to content and growth work.
I want content work to start from the current product surface, not from a pile of SEO page ideas.
The useful workflow starts by inventorying what already exists:
- which routes are already live
- which hubs already exist
- which posts are already published
- which missing pages are actually worth adding
- how the new content connects to the product and download path
In one content pass, the agent turned a broad idea into a staged plan, then shipped a set of pages tied to real product workflows.
The point was connection to the product surface: routes, hubs, metadata, build checks, production verification, and the actual workflows Speakmac supports.
For a product like this, landing pages, blog posts, download routes, pricing, checkout, and attribution are how people enter the product.
An agent that understands app code is useful. An agent that also understands the surrounding product surface is much more useful.
What Still Breaks
This setup still leaves plenty of manual judgment in the loop.
Bad telemetry stays bad. Stale data stays stale. Many support threads remain ordinary support threads. Some recurring reports deserve to be ignored.
It creates maintenance burden. The maps have to stay current. The automations have to be corrected when sources change. Event names have to stay meaningful. Old paths have to be marked archival. The agent still makes mistakes when the context is incomplete.
The whole system is patched together from repo docs, scripts, local files, analytics, warehouse data, billing, support, crash reports, local logs, and automations.
The patchwork is explicit.
The agent needs enough product context to know where to look, what to distrust, and when to say "we cannot answer this yet."
The Real Leverage
The useful part was making the product easier for the agent to inspect.
The codebase became more useful when it stopped being only implementation and started carrying product operating context:
- where truth lives
- what each signal means
- which joins are invalid
- how to validate releases
- how to read support
- how to measure acquisition
- how to evaluate models
- how to turn missing answers into better instrumentation
The product runs through the codebase, and the agent can help operate it because the codebase exposes the product's state, rules, and feedback loops.
The durable part is less product work dying in ambiguity.